Create a Golang tool to scrape comments from a HTML document
In this tutorial, we will create a tool in Golang to parse html files and extract html comments.
Make sure you have installed Golang and properly set up the environment variable. Check out Golang installation tutorial here.
1. Start by creating a file main.go and import the required Golang packages:
fmt - To print extracted html comments.os - To read HTML files from standard input (stdin)strings - To manipulate UTF-8 encoded strings.golang.org/x/net/html - To implement an HTML5-compliant tokenizer and parser.
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
2. Create a HTML Tokeniser in Golang
Create a Tokenizer. You should provide UTF-8 as os.stdin text to Tokenizer.
Assign a variable to html.NewTokenizer(os.stdin)
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
// Generates a html Tokenizer.
t := html.NewTokenizer(os.Stdin)
}
}
3. Tokenize all HTML tokens in Golang.
We need to repeatedly call t.New() to parse the next token. We can use a for loop to repeatedly move to the next token.
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
// Generates a html Tokenizer.
t := html.NewTokenizer(os.Stdin)
for {
// Moves the cursor to the next node in the tree.
tt := t.Next()
}
}
4. Tokenize all HTML tokens in Golang and handle errors.
Error handling is important to write smart code. Tokeniser returns the type of token or error.
If the Tokenizer returns an error we need to break the loop code immediately. So, use the html.ErrorToken function.
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
// Generates a html Tokenizer.
t := html.NewTokenizer(os.Stdin)
for {
// Moves the cursor to the next node in the tree.
tt := t.Next()
// html.ErrorToken is an error token.
if tt == html.ErrorToken {
break
}
}
}
5. Find HTML comments with tokenizer in Golang
Assign the token to a new variable.
Let's use the if (conditional) statement to execute a program if the token is a Comment Token(html.CommentToken).
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
// Generates a html Tokenizer.
t := html.NewTokenizer(os.Stdin)
for {
// Moves the cursor to the next node in the tree.
tt := t.Next()
// html.ErrorToken is an error token.
if tt == html.ErrorToken {
break
}
// Returns a token for the current token.
tc := t.Token()
// If the token is a CommentToken.
if tc.Type == html.CommentToken {
}
}
}
6. Manipulate strings in Golang
We can apply simple manipulation to the comment to make it more readable.
- Remove new line characters (\n). So, each comment becomes a one-liner.
strings.ReplaceAll(tc.Data, "\n", " ") or strings.Replace(tc.Data, "\n", " ", -1)
- Trim unwanted white space.
strings.TrimSpace(d)
- Do not print if the comment is an empty string. (
if d=="")
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
// Generates a html Tokenizer.
t := html.NewTokenizer(os.Stdin)
for {
// Moves the cursor to the next node in the tree.
tt := t.Next()
// html.ErrorToken is an error token.
if tt == html.ErrorToken {
break
}
// Returns a token for the current token.
tc := t.Token()
// If the token is a CommentToken.
if tc.Type == html.CommentToken {
// Replaces all new lines in token comment data with a white space.
d := strings.ReplaceAll(tc.Data, "\n", " ")
// Removes leading and trailing white space and returns a string.
d = strings.TrimSpace(d)
// If d is an empty string continue the loop without printing.
if d == "" {
continue
}
}
}
}
7. Return HTML comments in STDOUT in Golang
Now, we just have to print HTML comments on the console. and test if our program is working.
package main
import (
"fmt"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
// Generates a html Tokenizer.
t := html.NewTokenizer(os.Stdin)
for {
// Moves the cursor to the next node in the tree.
tt := t.Next()
// html.ErrorToken is an error token.
if tt == html.ErrorToken {
break
}
// Returns a token for the current token.
tc := t.Token()
// If the token is a CommentToken.
if tc.Type == html.CommentToken {
// Replaces all new lines in token comment data with a white space.
d := strings.ReplaceAll(tc.Data, "\n", " ")
// Removes leading and trailing white space and returns a string.
d = strings.TrimSpace(d)
// If d is an empty string continue the loop without printing.
if d == "" {
continue
}
// Println outputs d to stdout
fmt.Println(d)
}
}
}
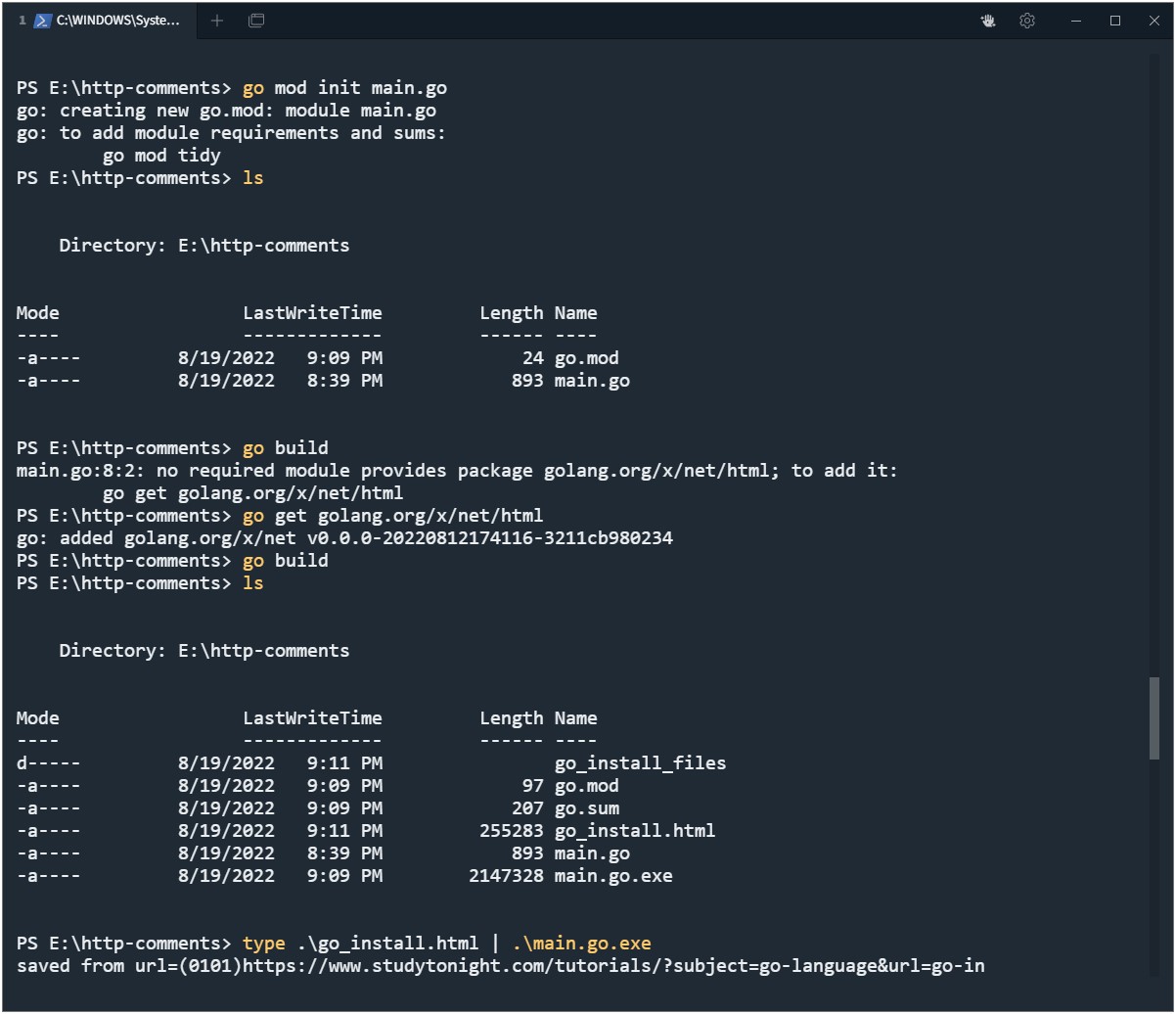
Build and run Golang HTML comment extractor program
Now open terminal and go to directory/folder and run these commands:
go mod init main.go
go get golang.org/x/net/html
go build
Conclusion
We have created a Golang tool to increase our attack surface. Now you can use regular expressions to fetch different interesting terms like URLs.